Exploratory Data Analysis
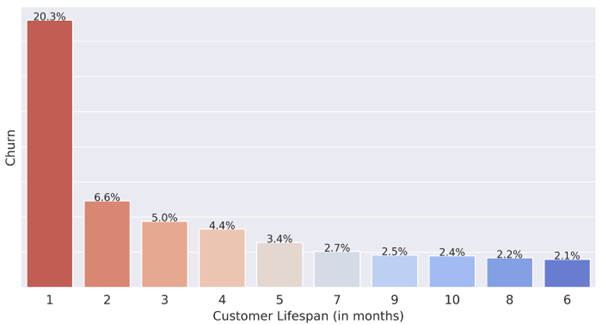
The analysis starts with Exploratory Data Analysis where the aim is to identify patterns that yield to customer churn. In the example below, the customer Lifespan (in months) is represented by the feature Tenure and customer churn is represented by the feature Churn, which is the target variable of this example. The bar chart below provides a good insight on how churn is distributed across the customer lifespan.
In the below example, we can see that the largest majority of customers cancel or do not renew their subscription in the first month, totaling 20.3% of customers that defect. Reasons for this high rate can be bad first experience, trial periods, or prepaid accounts that expire automatically if no top-up is done within a predefined time period.
In the next step of Exploratory Analysis, we focus on the categorical features and
how each feature is linked to the target feature
Churn. In the example below, we have split these features into three groups:
personal attributes, subscribed services and contract attributes.
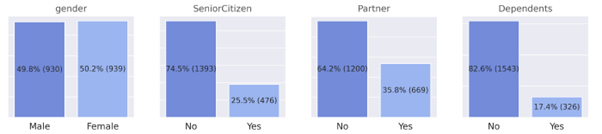
Personal Attributes:
In the dataset used for this example, the personal attributes available are:
Gender, SeniorCitizen, Partner, Dependents. The charts given below provide some meaningful insights such as:
Customers without dependents are four times more likely to churn.
Senior Citizens are three times less likely to churn.
Partners are almost two times less likely to leave.
Services Attributes:
This group of features indicates what kind of services customers subscribes to, or if it's not applicable. In our example, the list of features from this group include:
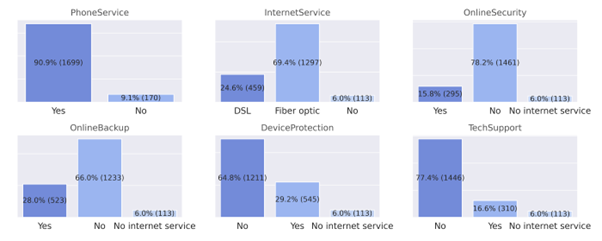
PhoneService, MultipleLines, InternetService, OnlineSecurity, OnlineBackup, DeviceProtection, TechSupport, StreamingTV and StreamingMovie.
The below charts show the features where
high discrepancies between the classes could be noticed. It gives insights regarding which kind of services the customers are more likely to defeat make use:
Majority of customers that cancel their service have Phone Service enabled.
Customers that have internet service as Fiber-Optic are more likely to cancel than those who have DSL.
Customers that do not have Online Security, Device Protection, Online Backup and Tech Support services enabled are more likely to leave.
Contract Attributes:
This group of features indicates contract aspects and gathers attributes such as
Contract, PaperlessBilling and Payment Method. Below charts give insights regarding the contract aspects that can make a subscriber more likely to churn:
The majority of customers that cancel their subscription have Month-to-Month Contract type and Paperless Billing enabled.
Customers that have Payment Method as Electronic Check are more likely to leave.
Partners are almost two times less likely to leave.

Sample Insights from Exploratory Analysis
Summary of Insights from Sample Data:
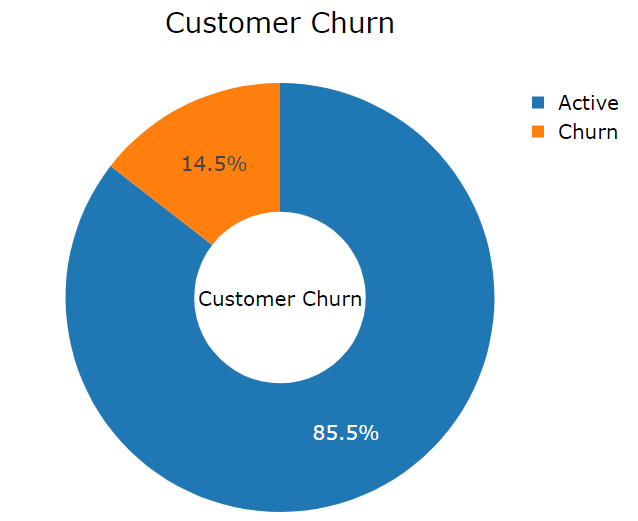
1. Overall Customer Churn is 14.5% in all states.
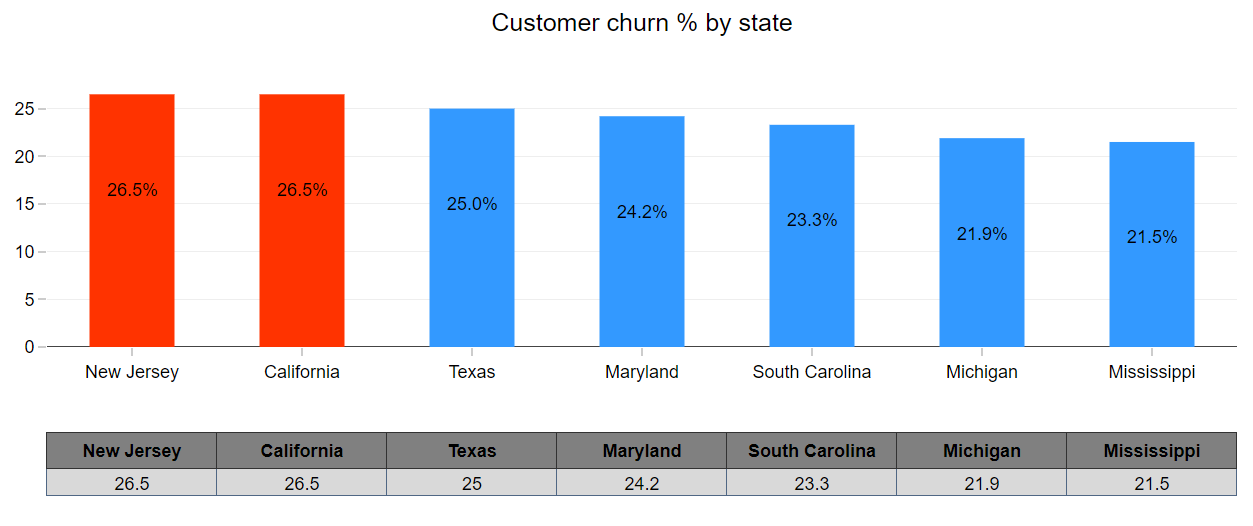
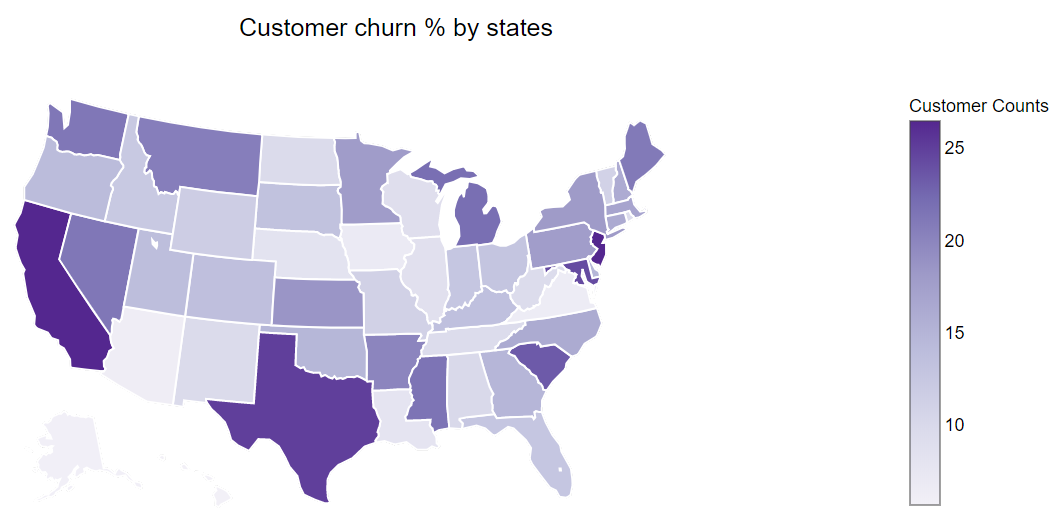
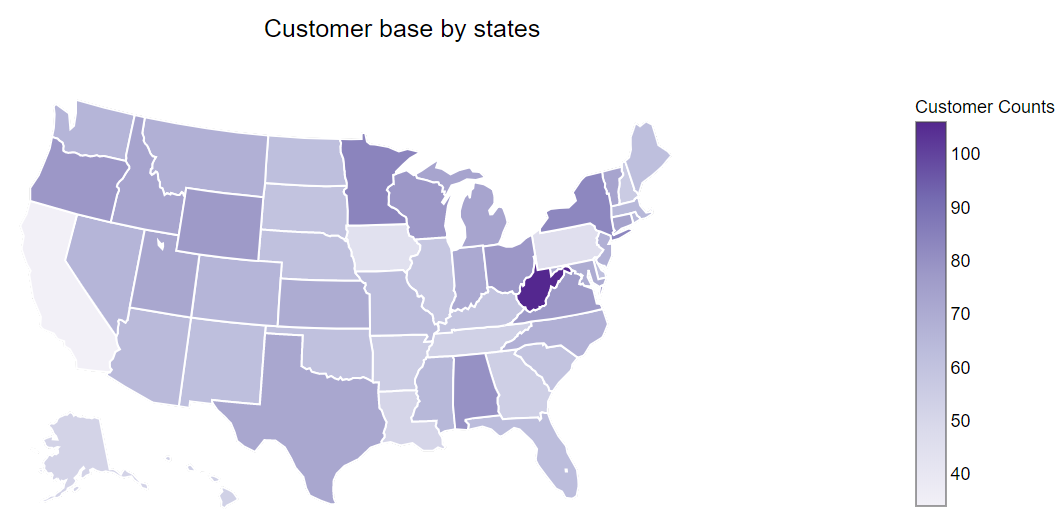
2. New Jersey and California states have the highest churn %.
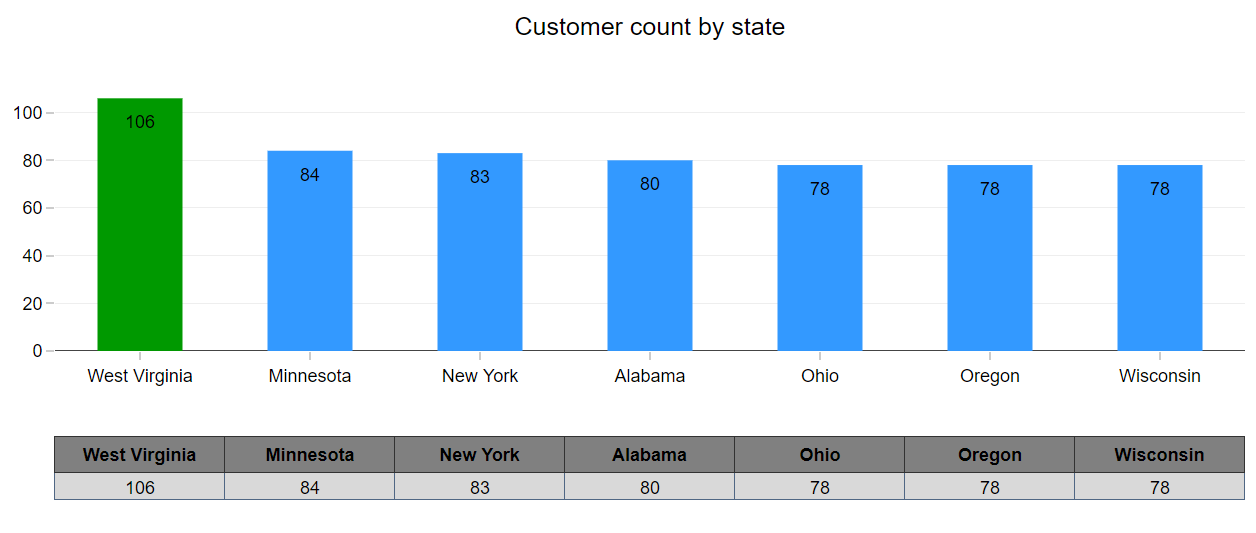
3. West Virginia has the highest customer base.
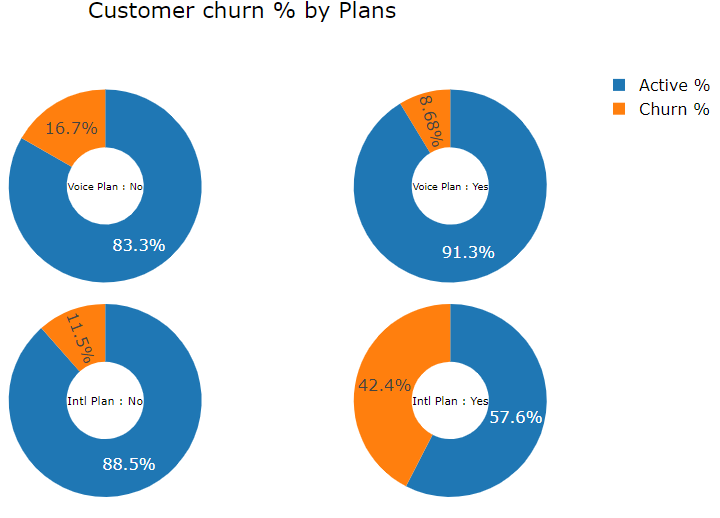
4. Churn Rate in customer group who have opted for international plan is high (42.4%).
5. Churn Rate in customer group who have no voice plan is high (16.7%).
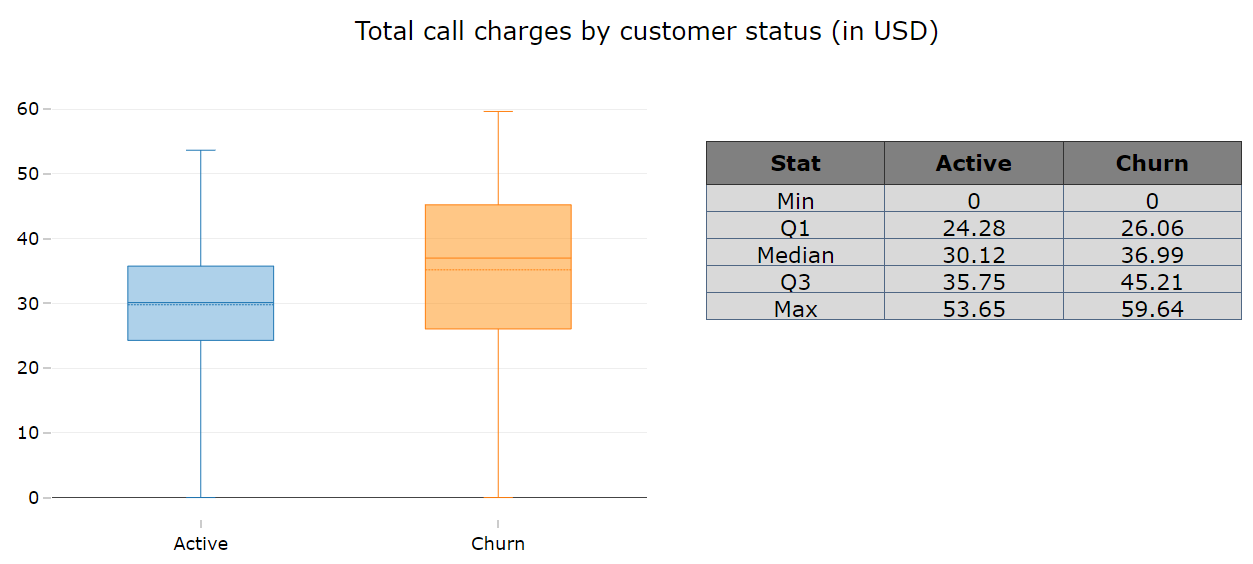
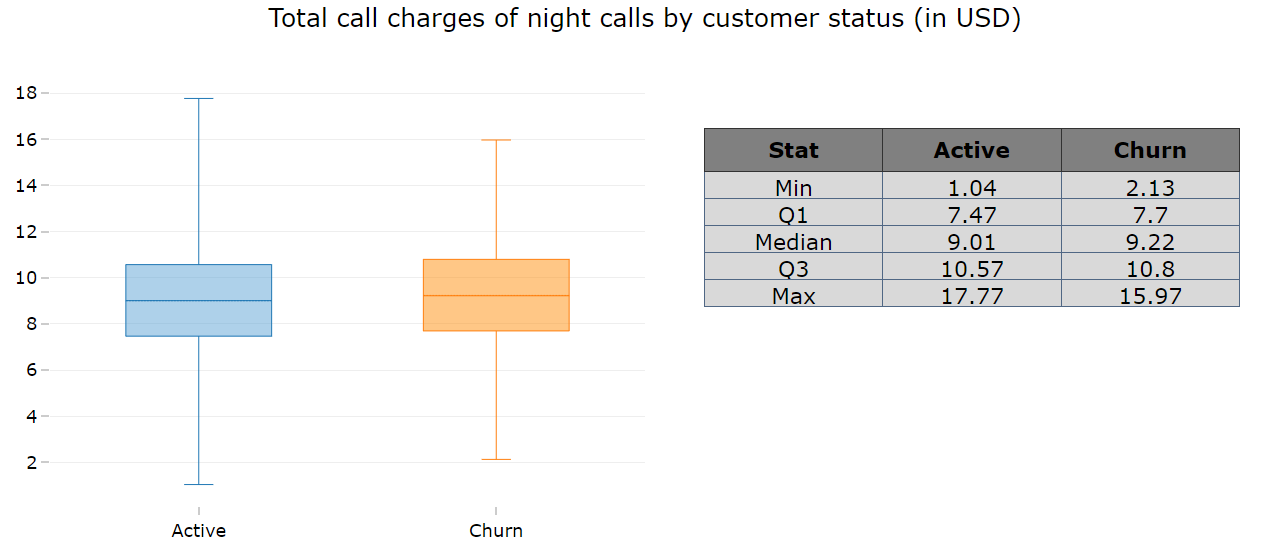
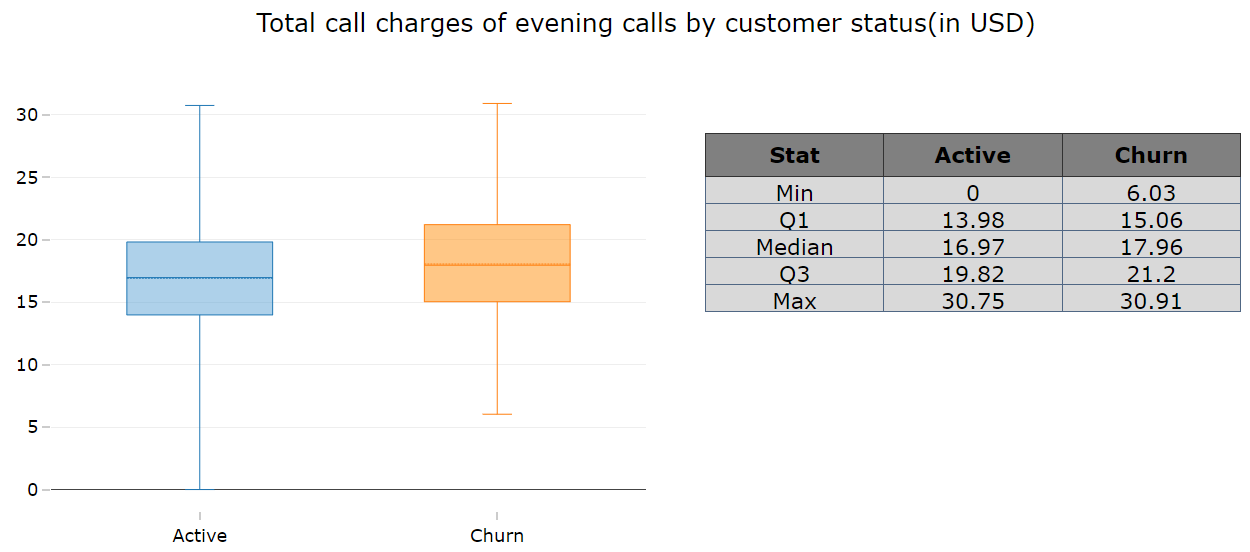
6. There is a clear pattern found in all type of call charges. That is, the customers who left the service provider paid more for all type of calls except night calls.
While Exploratory Analysis gives some insights into how each of the attributes is related to customer churn, we can't get any idea on relative influence of each of these attributes, i.e., which attributes in the data are influencing churn significantly, and which attributes do not have any influence or relatively lesser significance. It also does not provide a model to assess the probability of existing customer leaving the service provider.
We use Statistical techniques and Machine Learning algorithms to help us address these limitations as explained in the next section.
Developing a Machine Learning Algorithm to predict Customer Churn
We develop Machine Learning algorithms that are used to build analytical models which use historical data to build a model, which can predict the value of the outcome variable in new data where that value is not known. A good machine learning model can accurately predict the value of an outcome variable and thus help with quick decisions in the process workflow.
Predictive analytics uses an outcome variable, which, in the churn prediction case, is the churn indicator variable, for building the predictive model.
The typical steps that we follow to build a Machine Learning Model:
1. Gathering Data
2. Data Preparation
3. Choosing a model
4. Training
5. Evaluation
Gathering Data
The first step at this stage is to create an appropriate custom database. Data is collected from different sources (both internal and external sources). Data in our example dataset will have features like:
1. Internal Data
i. Customer Demographics (Age, Gender, Marital Status, Location etc.)
ii. Voice Call Statistics (Length of Calls, Local calls, National and International Calls)
iii. Data Usage (Data consumed in a given period, average monthly data consumption, time of data consumption etc.)
iv. Billing Information (Customer transaction history)
v. Credit History
vi. Customer Satisfaction Survey (CSAT)
vii. Call Center Data
viii. Customer Social Media interaction history
2. External Data
i. Competitor Information
ii. External Survey Data
Data Preparation
Data preparation typically involves the following tasks:
1. Selecting correct sample data.
2. Formatting Data to make it consistent.
3. Improving Data Quality.
4. Feature Engineering
5. Feature Selection
i. Trial and Error
ii. Dimensionality Reduction (Principle Component Analysis
iii. Statistical Significance
Choosing the Model
There are a few supervised algorithms available. Each algorithm differs in nature and produce different results based on the given data set. We choose the appropriate algorithms based on 2 factors: i. Nature of the data, and ii. The problem that we are solving. Below are the algorithms that we use for Churn Model Construction:
1. Logistic Regression
2. Random Forests
3. Gradient Boosting
4. Neural Networks
Training Models and Evaluation
The Model building activity involves construction of machine learning algorithms that can learn from historical data and make predictions or decisions on unseen data. Once our Churn Model is built, it is trained with training dataset, then validated with validation dataset, while fine tuning hyper parameters, and finally tested with test dataset. At each stage, chosen performance metric is observed to get desired performance level.